

We’ve undergone a lot of change over the past year. We’ve had the opportunity to grow and increase our breadth of services while keeping our flexible, scalable, and user-friendly platform. This journey is not a leap but a series of incremental steps moving us forward. We’ve been doing a lot of work under the hood to enable our expansion efforts, and we want to continue sharing what goes on behind the scenes with you.
Laying the groundwork for the future has to start with the backend infrastructure: hardware and networking. These can be overlooked with an eye on new features and services, but a strong foundation will allow us to build a more powerful platform.

More Power: Faster CPUs
Many of our existing regions now have AMD EPYC 7713 CPUs. We can compare this to one of the more common Zen 2 processors in our current fleet, the 7542, and still see a substantial raw performance increase.
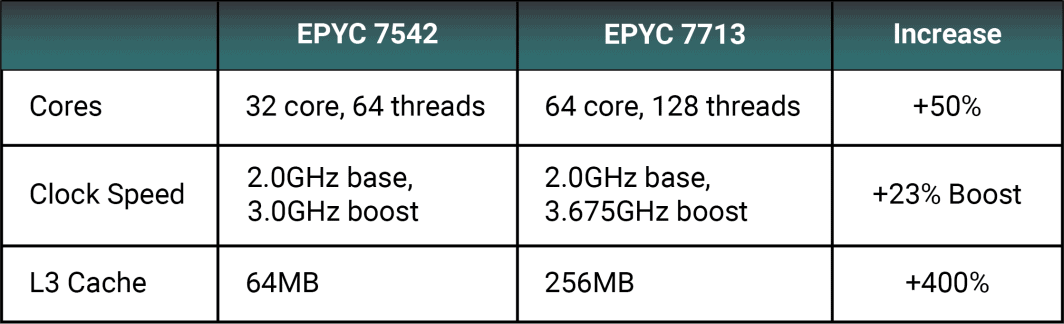
A 23% increase in boost clock speed will accommodate more demanding workloads. A higher core count decreases possible resource contention and bottlenecks from instructions running on a single execution engine.
The L3 cache increased by a whopping 400% going from 64MB to 256MB. A larger L3 cache prevents the CPU from frequently hitting the RAM for data. RAM is still faster than most storage formats, but CPU cache is built right into the processor and is significantly faster than RAM. A higher L3 cache provides performance boosts for memory-intensive applications, including gaming and video encoding.
Standard High-Speed Storage
We rolled out all NVMe block storage in 2021, which offers significant performance improvements over spinning disks or even SATA SSDs, but that’s only part of the story. Our compute plans come standard with local storage, which is uncommon with other providers, with only attached or temporary storage offered.
Block storage separates data into uniform “blocks,” making it ideal for high-performance file systems that need to spread across multiple VMs or hosts. Block storage is typically used locally, meaning a VM sits on the same hardware that the storage is directly connected to or as Network Attached Storage (NAS).
You see high performance in either configuration, but there’s a major difference between hitting a disk that’s physically attached to the same motherboard your server is running on vs. a NAS device connected via ethernet.
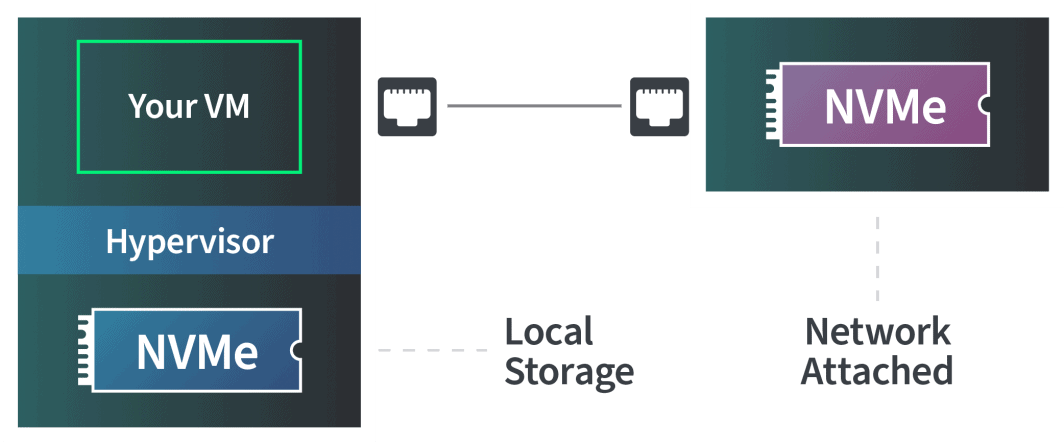
With two identical NVMe disks, you’ll always see higher performance from local storage over NAS. NAS, however, is more flexible and enables you to build massive storage arrays that can be accessed by multiple hosts at a larger scale. Our plans come with local storage, and we offer additional block storage that can be attached to a VM, all using NVMe.
Software RAID Controllers
KVM became our primary hypervisor in 2015 when we switched over from Xen. KVM significantly improved performance for VMs while using the same hardware. Fast forward to today, we’re continuing to build around Linux kernel virtualization with software RAID controllers as part of our new builds.
Hardware RAID controllers were once considered faster than software setups, but faster CPUs give software controllers a similar, if not improved, performance over hardware counterparts. As part of our builds in new data centers, we’re now using Linux kernel’s multiple device (MD) and kernel block drivers.

Linux software RAID controllers are managed through mdadm and grant our configurations a higher level of flexibility, including built-in hot-swapping capabilities without needing a hot-swapping chassis. These setups run regular consistency checks and perform automatic corrections of bad sectors.
SMBIOS
As of October 2022, our hosts are now equipped with System Management BIOS (SMBIOS). SMBIOS gives users the ability to query the MIF database and retrieve information about the compute instance. As long as your instance has booted/rebooted since we added this, you can use the dmidecode command to find the instance type and ID.
Run:
dmidecode -t1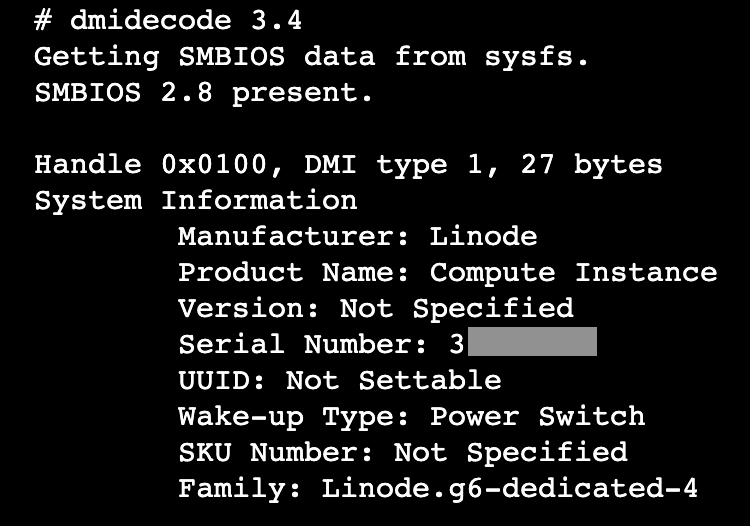
Previously, this information was not available on demand but can now be pulled from the terminal at any time. This is not a replacement for a local metadata API but can be a handy tool for custom scripting.
And More and More
As we continue to ramp up and develop new services, you can expect constant and consistent improvements across the board. We’ll keep you updated on all the minor and major details as we keep moving forward.
Resources: Blog | Technical Docs | Newsletter




Comments (3)
I’ve been a linode customer since April 2004, where it was a UserModeLinux (UML) based system, with a whopping 64Mb RAM and 3Gb disk (plus 1.5Gb disk for paying yearly).
Over the past 19 years your upgrades have meant I now have 4Gb RAM, 2CPUs, 80GB storage. A massive increase. All for the same price (well, until next month, anyway).
It’s good to see linode keeping up the tradition of improving the service!
The complicate one is when Linode instand got bigger storage than the current one.
It’s really hard to resize.
What if we need only create server capacity without increase storage?
What if we need only crease storage but not server capacity?
Jirou:Thanks for the suggestion! We’ve added it to our internal tracker and have passed along your feedback to our team. This way, the relevant teams can keep this in mind as we continue to improve our infrastructure and services.